
One Token = 4.4 Bytes: Why That’s a Problem for AI
Picture this: You’ve built a brilliant AI system, poured billions into training it, and it’s almost fluent in human language—except it keeps tripping over typos, emojis, and basic math. Why? The culprit is a little-known process baked into every major model: tokenization.
For most of us, tokenization isn’t even on the radar. It’s the process that breaks down words into chunks (tokens) so models like ChatGPT can make sense of them. But here’s the twist—this shortcut may actually be limiting what models can learn.
A new research study introduces the Byte Latent Transformer (BLT). This cutting-edge approach proposes a radical shift: what if we stopped slicing up text into pre-defined tokens entirely? What if the model could learn language directly from raw bytes?
The implications could be enormous for anyone using or building models for healthcare, science, or public service.
Tokenization: A Shortcut That’s Past Its Prime?
Back when computing power was limited and models were smaller, tokenization made a lot of sense. It compressed long texts into manageable parts and helped models learn faster.
Here’s an example of a few thousand autism research articles.
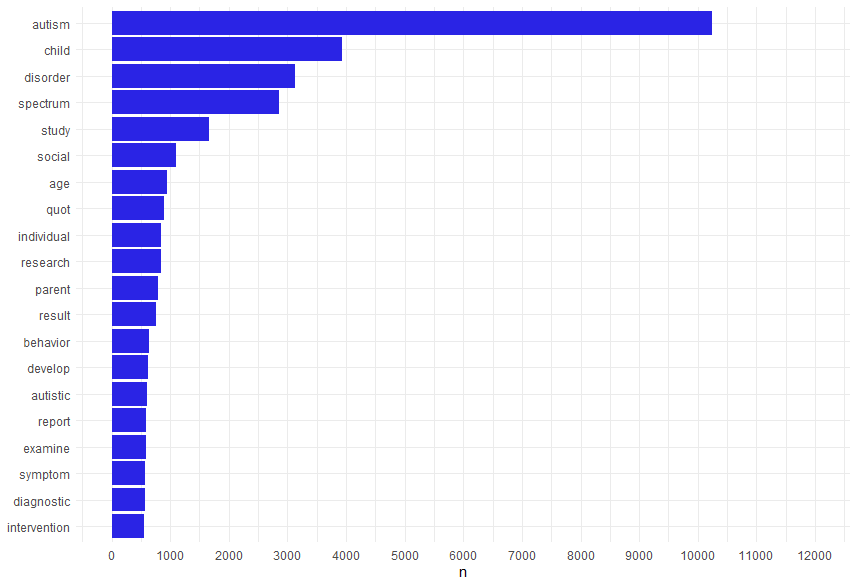
One popular method, Byte-Pair Encoding (BPE), chunks text into smaller, yet common fragments—“ing,” “tion,” even emojis. Here’s the same data in 2 character strings.
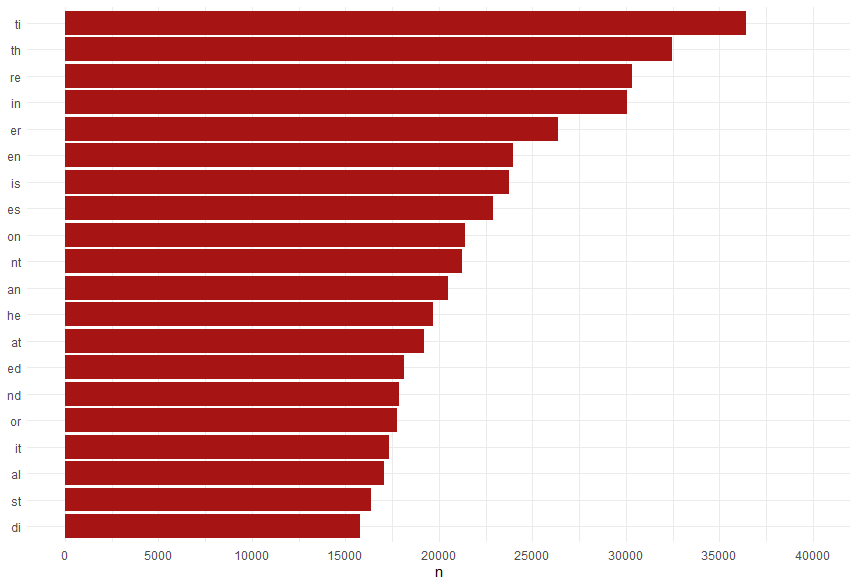
However, as models grew in size and ambition, tokenization began to reveal its flaws. Here are just a few documented issues:
- “Glitch tokens” like random Reddit usernames turning into unusable model outputs.
- Inconsistent math: some models can’t tell how many “r”s are in “strawberry” 🍓.
- Multilingual confusion: tokenizing across languages gets messy, fast.
What’s worse, these aren’t just annoying bugs—they represent fundamental blind spots. Models can miss context, butcher rare languages, and struggle with spelling or formatting quirks. That’s a big deal in fields like public health or law, where precision matters.
Enter BLT: A Model That Thinks in Bytes
The Byte Latent Transformer (BLT) is part of a new class of AI models that want to fix this by going straight to the source: raw bytes. Instead of relying on a fixed vocabulary of tokens, BLT learns how to group and understand text dynamically.
Here’s the innovation: BLT breaks text into “patches” using a small helper model that estimates how “surprising” each piece of text is. Boring phrases get grouped. Weird, surprising, or complex pieces get more attention. It’s like giving the model a magnifying glass when it needs to zoom in.
Then, BLT processes those patches using two main engines:
- A local model that reads every byte carefully.
- A global model that connects the big ideas across patches.
This structure gives BLT a huge edge: it can allocate compute power dynamically. Instead of treating every part of a sentence the same, it adapts. That means better performance, especially for tricky tasks like spelling correction, noisy text, and rare languages.
Why This Matters (Even If You’re Not an AI Researcher)
So why should people care about a niche architecture? Because the problems BLT solves are problems we all experience, just filtered through AI:
- Access and Equity: Models trained on tokenized English may miss nuance in dialects, minority languages, or medical jargon. Byte-level models close that gap.
- Cost and Efficiency: BLT shows potential to use fewer computing resources during inference, which could mean lower costs for running AI-powered services.
- Accuracy in Messy Contexts: Public health and scientific data aren’t always clean. With noisy text—think handwritten notes, web-scraped content, or multilingual surveys—BLT can stay smart where other models stumble.
And perhaps most importantly: BLT might finally let us train one model for many modalities (text, images, even DNA sequences), since everything boils down to bytes.
What’s Next for Token-Free AI?
The Byte Latent Transformer is still relatively new and has some caveats. Training it is slower. It relies on a helper model for deciding where patches begin. And it hasn’t yet outperformed traditional models on every benchmark.
But the momentum is real. Future improvements might:
- Fully integrate the patching mechanism to reduce complexity.
- Extend to images, audio, and other data types for seamless multimodal modeling.
- Optimize further for inference, allowing it to run faster on edge devices.
Still, one question looms: Will AI developers give up the control and familiarity of tokenizers for a more general—but less interpretable—approach?
If history is any guide, they just might. Because, as AI pioneer Rich Sutton famously put it: “The bitter lesson” is that general methods that leverage data and compute tend to win in the end.
Join the Conversation
- How do you think tokenization affects your field, be it language, law, or health?
- Should we prioritize generalization even if it costs interpretability?
- What would a token-free AI assistant mean for your work?
Let us know in the comments or on social.


